当下,航空AI助手正成为民航业数字化转型的“超级助手”——从旅客一句“下周一我要从北京飞广州,12点前到达”就能自动完成机票预订-11,到维修工程师在1.5分钟内获得排故方案、效率提升86%-7,再到智能客服以99%的识别率处理353个业务场景-30。2025年全球航空人工智能市场规模已达74.5亿美元,预计到2034年将增长至366.8亿美元,复合年增长率高达19.48%-95。许多技术学习者面临的尴尬是:用过聊天界面,却说不出背后的技术原理;被问“RAG和Agent有什么区别”,脑子一片空白。本文将从“为什么需要”出发,带你理清核心概念、看懂代码示例、记住面试要点,完整掌握航空AI助手的知识链路。
一、痛点切入:为什么航空业需要AI助手?

先看一个典型的传统航空客服场景。假设一名旅客想要改签航班,需要经历:
传统客服处理流程(伪代码)def traditional_customer_service(user_request): Step 1: 人工接收请求 agent = assign_human_agent() if not agent.is_available(): return "当前排队人数较多,请稍候..." Step 2: 人工查询系统 flight_info = agent.query_legacy_system("SELECT FROM flights...") 需要掌握复杂的SQL查询语言 Step 3: 人工计算差价 price_diff = calculate_price_difference(flight_info) Step 4: 人工生成回复 response = generate_response(price_diff) return response
传统方式的痛点极为明显:
成本高:人工客服占运营成本30%以上-65
效率低:复杂问题平均响应时间超过5分钟,高峰期客服中心不堪重负
响应慢:人工客服受班次限制,难以实现真正的7×24小时服务
数据门槛高:非技术背景人员无法直接查询业务数据,传统报表生成耗时耗力
相比之下,东航数科自主研发的智能问答系统AskData,常规数据查询响应时间已缩短至3秒以内,查询结果精准率超98%-1。这种效率差距,正是航空AI助手存在的根本原因。
二、核心概念讲解:大语言模型(LLM)
大语言模型(Large Language Model, LLM) 是基于Transformer架构,通过海量文本数据进行预训练,拥有数十亿乃至万亿参数的人工智能模型,核心目标是学习人类语言的语法、语义、知识、逻辑与规律,从而实现理解、生成、推理、对话等能力-46。
用生活化的比喻来理解:LLM就像一个读过人类几乎所有书籍的“超级学霸”——你问它任何问题,它都能根据阅读过的知识给出答案。但这位“学霸”有个致命缺点:它只读过书(训练数据截止到某个时间点),不知道实时发生的事情,也不知道它读的书里有哪些内容是错的。
LLM在航空AI助手中的核心能力包括:
自然语言理解:读懂“我要下周一12点前到广州”背后的语义——出发地、目的地、时间约束、优先级偏好
自然语言生成:用旅客听得懂的方式输出航班推荐和预订建议
逻辑推理:分析“CA976航班襟翼卡阻”的故障含义并关联相关处置方案-7
工具调用(Function Calling) :通过调用后端API完成查询航班、预订机票等实际操作-44
但航空领域对AI有特殊要求——容错率为零-7。通用大模型存在的“幻觉”(Hallucination,即生成虚假信息)风险,在航空决策中是绝对不可接受的。这就引出了下一个核心概念。
三、关联概念讲解:检索增强生成(RAG)
检索增强生成(Retrieval-Augmented Generation, RAG) 是一种结合信息检索与文本生成的技术范式——先从一个知识库中检索与问题最相关的文档片段,再将这些片段作为上下文输入给LLM,让LLM基于检索到的真实信息生成答案。
还是用刚才那位“超级学霸”来理解:RAG就是给这位学霸配了一台即时引擎。学霸不直接凭记忆回答,而是先航空公司的官方手册、规章文件,找到相关条款后,再根据这些“正确答案”来组织回答。这样,学霸永远不会“编造”答案。
RAG vs 纯LLM的本质区别:
| 对比维度 | 纯LLM | RAG |
|---|---|---|
| 知识来源 | 仅靠预训练记忆 | 实时检索+记忆 |
| 时效性 | 受训练数据截止时间限制 | 可访问最新文档 |
| 准确性 | 存在幻觉风险 | 基于真实文档,可追溯来源 |
| 航空适用性 | 不适合(安全要求极高) | ✅ 主流方案 |
这正是航空领域普遍选择RAG路线的根本原因。以Ameco飞机维修助手为例,研发团队在对比知识图谱和RAG后,最终拍板采用“RAG+标准化工作流”架构,核心考量就是“维修场景容不得AI‘瞎说话’,每个排故方案都必须可追溯”-21。
一个极简的RAG查询示例:
RAG工作流的核心步骤 def rag_airline_query(user_question): Step 1: 向量化用户问题 question_embedding = embed(user_question) Step 2: 从航空知识库中检索相关文档 示例:旅客问"行李托运规定" relevant_docs = vector_db.search(question_embedding, top_k=3) 返回:["国际航线行李限额2026版.pdf第8页", ...] Step 3: 将检索结果作为上下文,调用LLM生成答案 prompt = f"基于以下官方文档回答用户问题:\n{relevant_docs}\n\n用户问题:{user_question}" answer = llm.generate(prompt) return answer
四、概念关系与区别总结
理清三者的逻辑关系至关重要:
LLM是“大脑” :负责理解、推理、生成,是智能体的认知核心
RAG是“书架+工具” :为大脑提供实时、准确的参考材料,防止“胡编乱造”
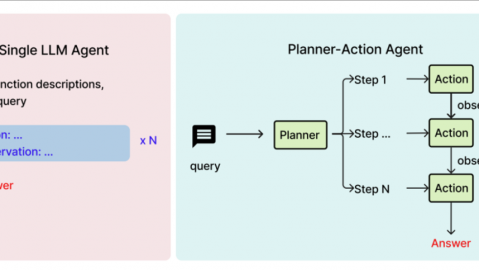
AI Agent(智能体)是“完整的人” :不仅有大脑(LLM)和知识库(RAG),还有手脚(工具调用能力),能够自主规划、执行多步任务
一句话总结:Agent = LLM + 记忆 + 规划 + 工具——Agent是最完整的智能体形态,LLM是它的“大脑”,RAG是它获取准确信息的“阅读器”。
💡 面试考点提醒:被问到“RAG和微调(Fine-tuning)有什么区别”时,记住——RAG不改模型参数,通过检索外部知识来增强回答;微调则是在特定领域数据上重新训练模型,改变模型内部参数。RAG适合知识频繁更新的场景,微调适合固定领域的深度优化。
五、代码示例:从零实现一个航空客服RAG
以下是一个完整的、可运行的航空AI助手核心模块示例:
航空客服RAG完整实现示例 import numpy as np from typing import List, Dict class AviationRAGChatbot: """航空客服RAG助手""" def __init__(self): 模拟知识库:航班信息、行李规定等 self.knowledge_base = { "CA1234": {"departure": "北京首都", "arrival": "上海虹桥", "status": "准点"}, "luggage_domestic": "国内航线经济舱免费托运20kg,公务舱30kg", "luggage_international": "国际航线免费托运2件,每件不超过23kg", "checkin_time": "国内航班提前45分钟停止值机,国际航班提前60分钟" } self.vector_store = self._build_vector_store() def _build_vector_store(self): """构建向量索引(简化版)""" 实际生产环境中使用FAISS、Chroma或专业向量数据库 vectors = {} for key, content in self.knowledge_base.items(): 使用简单的词频向量模拟(实际应用使用embedding模型) vectors[key] = self._simple_embed(content) return vectors def _simple_embed(self, text: str) -> np.ndarray: """简化版向量化(生产环境使用embedding模型)""" return np.array([hash(word) % 100 for word in text.split()[:10]] + [0]10)[:10] def retrieve(self, query: str, top_k: int = 2) -> List[str]: """检索最相关的知识文档""" query_vec = self._simple_embed(query) similarities = {} for key, vec in self.vector_store.items(): 余弦相似度计算 sim = np.dot(query_vec, vec) / (np.linalg.norm(query_vec) np.linalg.norm(vec) + 1e-8) similarities[key] = sim 返回Top-K个最相关文档 top_keys = sorted(similarities, key=similarities.get, reverse=True)[:top_k] return [self.knowledge_base[k] for k in top_keys if isinstance(self.knowledge_base[k], str)] def answer(self, user_query: str) -> str: """生成回答""" Step 1: 检索相关知识 retrieved_docs = self.retrieve(user_query) Step 2: 构造增强的Prompt context = "\n".join(retrieved_docs) enhanced_prompt = f"""【航空知识库参考】 {context} 【用户问题】 {user_query} 请基于上述官方航空知识库中的信息回答用户问题,不得编造不存在的信息。""" Step 3: 调用LLM生成答案(此处模拟LLM调用) 实际生产中使用OpenAI API、本地LLM或云端大模型 answer = self._simulate_llm_call(enhanced_prompt) return answer def _simulate_llm_call(self, prompt: str) -> str: """模拟LLM调用(实际替换为真实模型)""" 实际代码示例: from openai import OpenAI client = OpenAI() response = client.chat.completions.create(model="gpt-4", messages=[...]) if "行李" in prompt: return "根据航空规定,国内航线经济舱免费托运额度为20公斤,公务舱为30公斤。" elif "航班" in prompt and "CA1234" in prompt: return "CA1234航班当前状态为准点,从北京首都机场飞往上海虹桥机场。" else: return "您好,请问您想咨询航班动态、行李规定还是值机时间?" 使用示例 if __name__ == "__main__": assistant = AviationRAGChatbot() response = assistant.answer("CA1234航班现在什么状态?") print(f"AI助手回答:{response}") 输出:AI助手回答:CA1234航班当前状态为准点,从北京首都机场飞往上海虹桥机场。
📌 代码关键点解读:
retrieve方法:实现了核心检索逻辑——将用户问题与知识库文档进行相似度匹配answer方法:展示了RAG的完整流程——检索 → 增强上下文 → LLM生成生产环境优化:实际部署时使用专业的embedding模型(如BGE、text-embedding-3)和向量数据库(如FAISS、Milvus),并接入真实LLM API
六、底层原理与技术支撑
航空AI助手的底层技术栈主要依赖以下核心组件:
| 技术组件 | 作用 | 航空场景特殊性 |
|---|---|---|
| 嵌入模型(Embedding Model) | 将文本转化为向量,用于语义检索 | 需要理解航空专业术语如“客座率”“过站时间”“襟翼卡阻” |
| 向量数据库 | 存储和检索知识文档的向量索引 | 要求毫秒级检索速度,国航构建了可毫秒级检索的向量知识库-7 |
| 大语言模型(LLM) | 理解用户意图、生成回答 | 需具备航空专业知识,可通过领域微调增强 |
| 编排框架(Orchestration) | 协调检索、推理、工具调用等流程 | 支持多Agent协同,如客服场景中不同Agent分别处理预订、改签、退款-2 |
以中航集团“运行E+”AOC智能助手为例,其“双引擎知识中枢”架构正是上述技术组合的典范:向量知识库负责毫秒级检索,动态知识图谱负责逻辑推理,二者协同确保航空决策的准确性和可追溯性-7。
💡 对进阶学习者而言,深入学习的方向包括:RAG的检索优化策略(如HyDE、Self-RAG)、Agent的规划算法(如ReAct框架)、以及航空领域专属的模型微调技术(如LoRA架构)。后续文章将逐一展开讲解。
七、高频面试题与参考答案
面试题1:航空AI助手和通用聊天机器人有什么区别?
参考答案:
航空AI助手的核心区别体现在三个方面:1)知识来源——航空AI助手必须依赖官方知识库(手册、规章)而非模型记忆,通过RAG技术确保回答可追溯,避免“幻觉”;2)安全要求——航空领域容错率为零,必须采用“人主导,AI辅助”原则-7;3)业务闭环——不只是“能聊会说”,更要“能办会做”,如航旅纵横AI已实现从对话交互向业务级执行的跨越-11。
面试题2:请解释RAG的工作原理,以及它在航空场景中的优势。
参考答案:
RAG分三步工作:检索→增强→生成。优势有三:1)可追溯——回答基于真实文档,每个结论可找到依据,满足航空合规要求;2)时效性强——知识库可实时更新,无需重新训练模型;3)成本可控——相比持续预训练或全量微调,RAG的维护成本更低。航空维修场景的经验验证了这一点——RAG方案比知识图谱构建周期短、见效快,且能精准定位故障文档-21。
面试题3:什么是AI Agent?它与RAG是什么关系?
参考答案:
AI Agent = LLM + 记忆 + 规划 + 工具。RAG是Agent获取外部知识的手段之一。完整Agent比纯RAG多了“行动能力”——可以调用后端API完成订票、改签、退款等实际操作,而不仅仅是回答问题-2。简单说,RAG让AI“知道”正确答案,Agent让AI“做到”正确事情。
面试题4:航空AI落地面临的主要挑战是什么?
参考答案:
三大核心挑战:1)可信性——通用大模型的幻觉风险与航空安全要求之间的矛盾,需依赖RAG+知识图谱双重校验-7;2)实时性——运行控制等场景要求毫秒级响应,需要端侧部署而非云端依赖;3)合规性——民航业有严格的数据安全与监管要求,国内已出台首个民航端侧大模型技术标准(T/ISC 0102-2026)-25。AI系统在安全关键领域的决策可解释性仍面临巨大挑战-。
八、结尾总结
回顾全文核心知识点:
✅ LLM是航空AI助手的认知核心,提供语言理解与生成能力
✅ RAG通过检索外部知识库解决了LLM的幻觉问题,是航空场景的必备方案
✅ Agent在RAG基础上增加了工具调用和自主规划能力,实现从“回答”到“执行”的跨越
✅ 架构模式从国航的“双引擎知识中枢”到深航的“感知-决策-执行-优化”闭环,各有侧重但核心逻辑相通-7-30
⚠️ 易错点提醒:不要把RAG等同于“模型微调”,不要把Agent简单理解为“带工具的LLM”,面试时务必说清楚三者的区别与联系。
下一期我们将深入探讨航空AI助手Agent的工作流编排与多智能体协同,包括ReAct框架实现、LangGraph实战、以及航司客服场景下的多Agent任务分配策略。欢迎持续关注。