北京时间2026年4月10日发布
在游戏AI技术飞速演进的今天,“绝地求生AI助手”正从一个概念性产品逐步走向玩家终端。2026年初,KRAFTON正式公布了代号为“艾尔琳”的CPC(Co-Playable Character,定制化玩家角色)系统,成为游戏AI领域的重要里程碑-11。不少学习者在接触这一技术时往往陷入“会用但不懂原理”的困境:AI队友如何实时感知战场?端侧大模型如何在消费级显卡上流畅运行?目标检测与决策系统之间怎样协同?本文将从技术科普与原理讲解的双重角度,为你系统拆解绝地求生AI助手背后的完整技术链路。
📌 本文内容导航:痛点分析 → 核心架构拆解 → 底层技术原理 → 代码示例 → 面试要点。预计阅读时间15分钟,建议先收藏再细读。
一、痛点切入:传统NPC为何不够用?

传统游戏中的NPC(Non-Player Character,非玩家角色)遵循预设的脚本逻辑运行。以一个常见的“跟随玩家”功能为例:
传统NPC行为逻辑(简化示例) class TraditionalNPC: def update(self, player_position): 预设规则:如果玩家距离大于10米,则向玩家移动 if self.distance_to(player_position) > 10: self.move_towards(player_position) 预设规则:如果看到敌人,则攻击 elif self.has_enemy_in_sight(): self.attack()
这段代码暴露了三个核心痛点:
耦合性高:行为逻辑与场景硬编码,新地图或新装备出现时需手动更新规则。
扩展性差:想增加“战术商量”“语音交互”等功能,几乎要重写整个行为系统。
响应僵化:NPC无法理解“帮我去P城搜三级甲”这种语义化指令。
正是这些局限,催生了新一代绝地求生AI助手的出现——它不再是被动执行脚本的工具,而是具备感知、理解与决策能力的智能队友。
二、核心概念讲解:CPC与PUBG Ally
2.1 CPC(Co-Playable Character)——可协作玩家角色
定义:CPC是由KRAFTON提出的新型AI角色范式,区别于传统NPC,CPC的设计初衷是与玩家并肩作战、默契配合,而非单纯被操控-11。
类比理解:传统NPC像一台“自动售货机”——你按下按钮,它给你固定输出。而CPC更像一个“真人搭档”——它能听懂你说“帮我架枪”,会根据战况主动提建议,甚至在你不小心阵亡后想办法复活你。
CPC的四大核心能力(以PUBG Ally“艾尔琳”为例):
游戏水平在线,能与玩家保持行动同步;
理解自然语音指令,无需记忆复杂命令格式;
掌握游戏专属术语,听懂“舔包”“架枪”“拉枪线”等俚语;
具备自然交流能力,能倾听、回应甚至开玩笑-11。
2.2 PUBG Ally——CPC在绝地求生中的落地实现
定义:PUBG Ally是KRAFTON基于NVIDIA ACE技术为《绝地求生》打造的AI同伴系统,支持玩家通过自然语言与AI队友交互-2。
与CPC的关系:CPC是概念范式(“是什么”),PUBG Ally是具体实现(“怎么做”)。CPC定义了AI角色的设计理念和目标形态,PUBG Ally则是这一理念在绝地求生场景中的工程落地。
一句话概括:CPC是“设计思想”,PUBG Ally是“工程实现”。
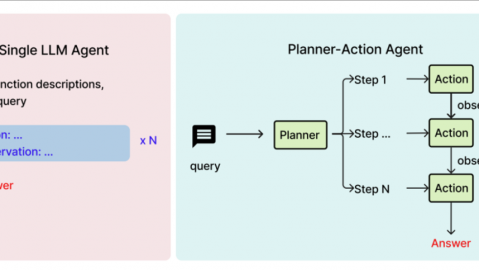
三、核心技术架构:双层决策系统
GDC 2026上,KRAFTON首次公开了AI队友“艾尔琳”的双层架构方案-11。
3.1 架构全景图
┌─────────────────────────────────────────────────────────┐ │ 玩家语音输入 │ └─────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────┐ │ 一号系统(LLM/SLM驱动) │ 二号系统(规则模型驱动) │ │ - 语义理解与意图识别 │ - 毫秒级行动响应 │ │ - 战术对话与策略讨论 │ - 稳定可预测的行为输出 │ │ - 处理复杂/非标场景 │ - 覆盖核心战斗逻辑 │ └─────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────┐ │ 融合层(行动调度) │ │ 二号系统生成基础指令 → 一号系统按需修改/补充 │ └─────────────────────────────────────────────────────────┘
3.2 为什么需要双层架构?
这是一个经典的“智能与效率权衡”问题:
| 维度 | 一号系统(LLM/SLM) | 二号系统(规则模型) |
|---|---|---|
| 响应速度 | 较慢(需模型推理) | 极快(毫秒级) |
| 智能程度 | 高(理解语义、灵活应对) | 低(仅执行预设规则) |
| 适用场景 | 对话、战术决策、异常处理 | 射击、移动、拾取等基础操作 |
| 稳定性 | 存在一定不确定性 | 100%可预测 |
在绝地求生这种TTK(Time To Kill,击杀耗时)可能不足1秒的竞技游戏中,纯LLM驱动的AI无法满足实时性要求-11。KRAFTON的方案是:二号系统负责“快”,一号系统负责“智” ,两者协同工作。
3.3 核心数据流
AI队友的感知输入并非直接识别游戏画面,而是接收结构化的游戏数据(位置、时间、物资、敌情等),再转化为文本描述供模型理解-11。这种设计规避了纯视觉方案的计算开销,同时保证了信息准确率。
运行机制流程:
玩家语音输入 → 语音转文字
结构化游戏状态 → 转换为文本描述
一号系统(LLM) → 理解意图,生成战术决策
二号系统(规则模型) → 执行具体动作(移动、射击等)
文字转语音 → AI作出语音回应
四、底层技术支撑
4.1 端侧SLM(Small Language Model,小型语言模型)
与传统AI依赖云端大模型不同,PUBG Ally的核心语言模型运行在玩家本地电脑上-13。这一设计选择背后有多重考量:
延迟:避免网络往返耗时,确保实时交互体验。
隐私:玩家语音数据不上传云端,保障信息安全。
成本:无需维护云端推理集群,降低运营成本。
实测数据:RTX 3060显卡即可实现60帧流畅运行,AI响应延迟控制在2秒以内-11。
4.2 NVIDIA ACE技术
ACE(Avatar Cloud Engine)是英伟达提供的端侧AI框架,使AI角色能够“感知、规划、行动”-。它集成了语音识别、小型语言模型、语音合成三大模块:
玩家语音
语音识别ASR
小型语言模型SLM
语音合成TTS
AI语音回应
行动指令生成
游戏动作执行
ACE还提供了长期记忆功能——AI能记住往局的对局结果和玩家偏好,在后续游戏中提供更个性化的配合-5。
4.3 目标检测技术(以YOLOv8为例)
虽然KRAFTON官方采用结构化数据输入方案,但了解YOLOv8这类目标检测技术对于理解游戏AI的底层视觉能力仍有重要意义。
YOLOv8(You Only Look Once version 8)是Ultralytics公司发布的新一代目标检测模型,采用Anchor-Free检测策略和CIoU等先进损失函数-20。在游戏场景中,它被广泛用于实时识别敌人、道具等目标。技术社区已有基于YOLOv8+FPS游戏的完整开源项目,单帧推理延迟可控制在10ms以内-50。
YOLOv8游戏目标检测示例(学术研究用途) from ultralytics import YOLO import cv2 加载预训练模型 model = YOLO('yolov8n.pt') 捕获游戏画面(假设已通过截图获取frame) results = model(frame, conf=0.45) 置信度阈值0.45 解析检测结果 for box in results[0].boxes: cls = int(box.cls[0]) 目标类别 conf = float(box.conf[0]) 置信度 xyxy = box.xyxy[0].tolist() 边界框坐标
4.4 强化学习决策框架
在AI决策层面,PPO(Proximal Policy Optimization,近端策略优化)算法被广泛采用。其核心优势在于策略剪辑机制,能有效避免训练崩溃,适配游戏的离散动作空间-50。
PPO与传统Q-Learning的核心区别在于:Q-Learning学习“某个状态下做某个动作有多好”,而PPO直接优化“在某个状态下应该选哪个动作的概率分布”,收敛更快且更稳定。
五、极简代码示例:游戏状态感知
以下代码模拟了AI队友感知游戏环境并作出反应的简化逻辑:
import asyncio from typing import Dict, List class GameState: """结构化游戏状态数据(类似KRAFTON方案的输入格式)""" def __init__(self): self.player_hp: int = 100 self.player_position: tuple = (0, 0) self.enemies: List[Dict] = [] 敌情列表 self.loot_nearby: List[str] = [] 附近物资 self.zone_status: str = "safe" 圈状态 class PUBGAlly: """AI队友核心类""" def __init__(self): self.slm = SmallLanguageModel() 端侧语言模型 self.rule_engine = RuleEngine() 规则模型(二号系统) async def perceive_and_act(self, game_state: GameState, voice_input: str = None): Step 1: 语音识别与意图解析(一号系统) intent = self.slm.parse(voice_input) if voice_input else None Step 2: 二号系统生成基础行动指令(毫秒级) base_actions = self.rule_engine.get_actions(game_state) Step 3: 若存在语音指令,一号系统修改/补充行动 if intent: enhanced_actions = self.slm.refine_actions(base_actions, intent) else: enhanced_actions = base_actions Step 4: 执行行动并生成语音回应 self.execute(enhanced_actions) response = self.slm.generate_response(game_state, intent) return response 使用示例 ally = PUBGAlly() state = GameState() state.enemies = [{"distance": 50, "direction": "NE"}] response = await ally.perceive_and_act(state, "帮我架住东北方向") print(f"AI回应:{response}")
代码要点解读:
游戏状态以结构化数据形式输入,而非原始画面像素;
双系统协同:规则模型保证响应速度,语言模型提供智能增强;
所有模块在本地运行,无需云端依赖。
六、高频面试题与参考答案
Q1:绝地求生AI助手为什么选择端侧部署而非云端?
参考答案(建议背诵核心三点):
延迟要求:竞技游戏对响应速度极其敏感,云端推理的网络往返时间(RTT)不可接受;
隐私安全:玩家语音数据不上传云端,降低隐私泄露风险;
成本控制:避免大规模云端推理集群的运营成本。官方实测RTX 3060显卡即可流畅运行-11。
💡 面试加分点:进一步提到端侧部署还意味着“离线可用”,不受网络波动影响。
Q2:解释双层架构的设计动机及其优劣。
参考答案:
设计动机:解决“智能与效率”的矛盾。纯LLM驱动的AI无法满足射击游戏的毫秒级响应要求-11。
方案:二号系统(规则模型)负责基础动作执行,一号系统(LLM/SLM)负责语义理解和战术决策,两者协同工作。
优势:兼顾响应速度与智能交互;
劣势:架构复杂度上升,两套系统间的调度逻辑需精心设计。
💡 面试加分点:可以类比“人类反应”——肌肉记忆(快但简单)与大脑思考(慢但灵活)的协同机制。
Q3:YOLOv8在游戏AI中扮演什么角色?与传统目标检测方法有何不同?
参考答案:
角色:提供实时游戏画面中敌人、道具等目标的视觉识别能力,是“感知层”的关键组件。
核心优势:单次前向传播即可完成整张图片的目标检测与定位,推理速度极快-20。单帧延迟可控制在10ms以内-50。
与传统方法对比:传统方法如滑动窗口+分类器需多次计算,YOLOv8“只看一次”即输出全部结果,速度提升1-2个数量级。
Q4:什么是PPO算法?它在游戏AI中解决什么问题?
参考答案:
定义:PPO(Proximal Policy Optimization,近端策略优化)是一种强化学习策略优化算法。
核心机制:通过策略剪辑(Clipping)限制每次更新的幅度,避免训练崩溃。
解决的问题:游戏AI需要在与环境的持续交互中自主学习最优策略,PPO提供了稳定、高效的训练框架,尤其适合离散动作空间的游戏场景-50。
七、总结与进阶预告
核心知识点回顾
| 层次 | 关键技术 | 一句话总结 |
|---|---|---|
| 概念层 | CPC vs NPC | CPC是“可协作的队友”,NPC是“可操控的工具” |
| 架构层 | 双层决策系统 | 规则模型保“快”,语言模型保“智” |
| 底层 | SLM + ACE + YOLOv8 + PPO | 端侧推理 + 视觉感知 + 强化决策 |
| 工程 | 本地部署 + 结构化输入 | RTX 3060可跑,2秒内响应 |
易错点提示
⚠️ 混淆 CPC 与 PUBG Ally:前者是概念范式,后者是具体实现。
⚠️ 误以为AI队友直接识别游戏画面:实际上是接收结构化数据。
⚠️ 忽略双层架构的存在:只谈LLM不谈规则模型,理解不完整。
进阶学习方向
下一篇我们将深入探讨多模态AI Agent在游戏中的实现,包括视觉语言模型(VLM)如何让AI直接“看懂”游戏画面、如何设计更复杂的多Agent协作系统,以及2026年AI Agent面试中的系统设计进阶题型-56。敬请期待。
本文所有技术数据均来源于KRAFTON GDC 2026官方演讲及NVIDIA公开技术文档,截止2026年4月10日。