从代码补全到智能体编程,一文搞懂AI编码助手到底是什么、怎么工作、面试怎么答
一、开篇:为什么每个程序员都应该搞懂AI编码助手
AI编码助手,正在从根本上改写软件开发的规则。根据Gartner的预测,到2028年,75%的企业软件工程师将把AI编码助手作为日常工具来使用,而这一比例在2023年初尚不足10%-41。据行业数据显示,AI编程工具日均代码生成量已突破10亿行-48。
但现实是——很多开发者每天在IDE里点着“Tab补全”,却说不出AI编码助手到底是怎么工作的;知道它能写代码,却不理解它为什么会“胡说八道”;日常用得很顺手,面试时却被问得哑口无言。

这是当下最普遍的学习痛点:只会用,不懂原理。
本文将围绕以下主线展开:AI编码助手是什么→为什么需要它→核心概念拆解→概念之间的区别→代码示例演示→底层原理→高频面试题。全文兼顾“看得懂”和“用得上”,帮你建立完整的知识链路。
二、痛点切入:为什么我们需要AI编码助手?
在AI编码助手出现之前,传统编程工作流程是什么样的?下面这段代码演示了开发者在实现一个简单函数时,需要经历哪些步骤:
传统实现方式:手动完成每一个细节 def calculate_discount(price, discount_rate): 步骤1:参数校验 if price <= 0: raise ValueError("价格必须大于0") if discount_rate < 0 or discount_rate > 1: raise ValueError("折扣率必须在0到1之间") 步骤2:计算折扣 discounted_price = price (1 - discount_rate) 步骤3:精度处理 discounted_price = round(discounted_price, 2) 步骤4:返回结果 return discounted_price
这看似只有十几行代码,但背后包含了大量的机械性劳动:参数校验要自己写、业务逻辑要手动推导、精度问题要主动考虑、变量命名要反复斟酌。在传统模式下,开发者需要:
手动查阅API文档
手动编写重复性的模板代码
手动处理边界情况和异常逻辑
手写单元测试
这些工作机械重复、容易出错,而且本质上和业务创新没有关系。AI编程工具正是为解决这些痛点而生——它通过代码生成、智能补全、错误修复、文档生成四大核心能力,直接降低编码的机械性工作量-34。
三、核心概念讲解:什么是AI编码助手?
定义
AI编码助手(AI Coding Assistant) = 「大语言模型 + 代码专属数据」驱动的开发提效工具-2。
拆解这个公式:
大语言模型(LLM,Large Language Model) :在海量文本数据上训练而成的神经网络,具备理解和生成自然语言的能力-1。
代码专属数据:在通用大模型基础上,额外使用数十亿行开源代码进行专项训练,使模型“学会”编程语法、设计模式、API用法等。
用生活化类比来理解:可以把LLM想象成一个读过全世界所有编程书籍的实习生——它有海量的知识储备,但需要你用清晰的需求(提示词)来“唤醒”它。而代码专属数据训练,就像让这个实习生不仅读过书,还实际敲过几十万行代码。
核心能力
AI编码助手的核心能力可归纳为5件事-2:
代码补全:行级、函数级、文件级的智能补全
自然语言→代码:根据注释或需求描述直接生成功能代码
代码解释与重构:理解老代码逻辑,提出优化建议
自动化测试:一键生成单元测试、Mock数据
端到端交付:从需求分析到代码生成再到部署的全流程辅助
一句话总结:AI编码助手把产品经理或程序员用自然语言描述的“想要什么”,翻译成可运行、可上线的工程代码。
四、关联概念讲解:LLM vs AI编码助手
很多初学者容易把“大语言模型”和“AI编码助手”混为一谈,这里必须厘清。
概念B:大语言模型(LLM)
大语言模型是一种基于Transformer架构的深度神经网络,通过在海量文本数据上进行预训练,学习语言的统计规律和语义表征。OpenAI的GPT系列、Meta的Code Llama、阿里的通义千问、腾讯的混元都属于大语言模型。
关系辨析:思想 vs 实现
AI编码助手是“应用”,大语言模型是“引擎”。
LLM是底层能力:提供语义理解、文本生成的基础能力
AI编码助手是上层产品:在LLM之上封装了代码补全逻辑、IDE集成、代码过滤等工程化功能
打个比方:LLM是发动机,AI编码助手是整车。发动机(LLM)决定了动力性能,但你需要整车(AI编码助手)的底盘、轮胎、方向盘——也就是IDE集成、代码过滤、上下文管理等——才能真正开上路。
差异对比
| 维度 | LLM | AI编码助手 |
|---|---|---|
| 定位 | 基础模型 | 垂直应用 |
| 训练数据 | 通用文本 + 代码 | 代码 + 编程上下文 |
| 输入形式 | 文本提示词 | IDE上下文 + 用户输入 |
| 输出 | 原始文本 | 代码建议、解释、重构 |
| 核心能力 | 语言建模 | 编程辅助 |
五、概念关系与区别总结
用一句话串联上述所有概念:
AI编码助手是基于大语言模型(LLM) 构建的工程化应用,通过在代码数据上微调训练,将LLM的通用的语言理解能力聚焦到编程场景,再通过IDE集成、代码过滤、上下文管理等工程化手段,为开发者提供智能化的编码辅助。
记忆要点:
LLM是“大脑”(基础能力)
代码微调是“专业训练”(聚焦编程)
AI编码助手是“完整的工具”(工程封装)
六、代码示例演示:从传统编码到AI辅助
为了更好地理解AI编码助手到底做了什么,我们用同一个任务来对比传统实现和AI辅助实现。
任务:实现一个购物车总价计算函数,输入商品列表,输出总金额。
传统实现方式(手动编码)
def calculate_cart_total(products): 步骤1:参数类型检查 if not isinstance(products, list): raise TypeError("products 必须是数组") total = 0 步骤2:遍历累加 for product in products: 手动检查每个字段 if not isinstance(product, dict): continue price = product.get("price", 0) quantity = product.get("quantity", 1) if not isinstance(price, (int, float)): price = 0 if not isinstance(quantity, int): quantity = 1 total += price quantity 步骤3:保留两位小数 total = round(total, 2) return total
开发这个函数,开发者需要手动思考:参数校验、类型检查、字段缺省值、精度处理……大约需要5-10分钟。
AI编码助手辅助方式
开发者只需在代码中写一行自然语言注释,AI编码助手就能自动生成对应代码:
计算购物车总金额,输入商品列表,每个商品包含price和quantity字段 需要做参数类型检查、异常处理,返回保留两位小数的总金额
GitHub Copilot、Cursor、CodeBuddy等工具会基于注释和上下文,实时生成完整的函数实现,整个过程通常只需几秒钟-34。
执行流程说明
当你在IDE中输入注释时,AI编码助手的执行流程如下:
收集上下文:读取当前文件内容、光标前后代码、项目结构
构建提示词:将注释和上下文组合成模型可理解的输入
调用模型:将提示词发送给LLM(本地或云端),等待输出
过滤与建议:对模型输出进行安全过滤,展示在IDE中
用户确认:开发者按Tab接受,或继续修改调整
七、底层原理与技术支撑
AI编码助手之所以能够“理解”代码并生成建议,底层依赖几个关键的技术支撑点:
1. 基于Transformer的代码建模
AI编码助手的核心模型采用Transformer架构——一种通过“自注意力机制”让模型能够关注输入序列中不同位置之间关系的深度神经网络架构。训练数据来源包括GitHub上的海量开源代码仓库、代码注释与文档、Stack Overflow问答等-11。
简单理解:模型通过学习数十亿行代码,掌握了代码的“统计规律”——什么情况下会出现什么代码模式、变量该如何命名、常见的API怎么调用。它本质上是一台模式匹配机器,通过提示词来“提取”训练过程中学习到的统计表征-1。
2. 微调与RLHF
基础LLM通过微调(Fine-tuning) ——在精选的代码示例上进行针对性训练——和RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习) ——通过人类标注者的偏好反馈来优化模型行为——进一步优化,使其能遵循编程指令、产出高质量代码-1。
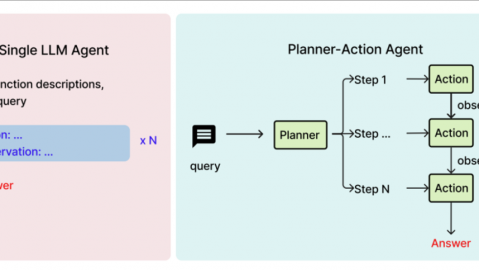
3. 代码智能体架构(Agent架构)
最新的AI编码助手已经进化出 “代码智能体(Coding Agent)” 架构。Anthropic的工程文档将其工作模式概括为四个阶段-1:
收集上下文:读取项目文件、依赖关系、历史记录
采取行动:执行代码生成、文件修改、命令运行
验证工作:运行测试、检查编译错误
循环:重复上述过程直至任务完成
底层技术细节(如KV缓存优化、推理加速、上下文压缩等)属于进阶内容,本文不做深入展开,后续系列文章会单独讲解。
八、高频面试题与参考答案
问题1:什么是AI编码助手?它和大语言模型有什么关系?
参考答案:AI编码助手是基于大语言模型构建的代码开发提效工具。大语言模型提供语义理解与文本生成的基础能力,而AI编码助手通过代码数据微调、IDE集成、代码过滤等工程化手段,将LLM能力聚焦到编程场景中。两者关系可以概括为:LLM是引擎,AI编码助手是整车。
踩分点:给出定义、说明两者关系、点出工程化封装。
问题2:AI编码助手的代码推荐是基于什么原理?
参考答案:核心基于Transformer架构和模式匹配机制。模型在海量代码数据上预训练,学习代码的统计规律。当接收到上下文时,通过注意力机制分析输入,然后基于训练中学习到的模式,预测下一个最可能的代码token。这是一个概率生成过程,而非真正“理解”业务语义。
踩分点:提到Transformer、注意力机制、预训练、概率生成(而非理解)。
问题3:传统IDE自动补全和AI编码助手有什么本质区别?
参考答案:传统IDE补全基于词法分析和静态语法解析,只能根据已输入的前缀匹配预设模板。AI编码助手基于大语言模型,能理解代码语义和上下文意图,可以跨函数、跨文件进行推理,生成完整的代码逻辑而非仅补全单词。
踩分点:传统方案是规则匹配/语法解析,AI方案是语义理解/大模型推理。
问题4:AI编码助手有哪些局限性?
参考答案:第一,上下文窗口有限,大项目信息可能“记不住”;第二,存在幻觉问题,可能生成不存在的API或错误逻辑;第三,代码安全性无法保证,可能引入漏洞或违反合规要求;第四,无法真正理解业务语义,仅做统计模式匹配。
踩分点:上下文限制、幻觉问题、安全风险、非真正理解。
问题5:如何提高AI编码助手的代码生成质量?
参考答案:①写清晰、具体的自然语言注释;②提供足够的上下文,如函数签名、类型定义;③将复杂任务拆解为小步骤;④利用反馈循环,对不合适的建议进行纠正;⑤结合单元测试验证生成结果的正确性。
踩分点:提示词优化、上下文提供、任务拆解、验证机制。
九、结尾总结
核心知识点回顾
本文围绕AI编码助手这一核心主题,讲解了以下内容:
| 模块 | 核心要点 |
|---|---|
| 概念定义 | AI编码助手 = LLM + 代码专属数据驱动的提效工具 |
| 痛点分析 | 传统编程机械性劳动多,AI编码助手降低重复工作量 |
| 核心原理 | Transformer架构 + 代码数据预训练 + 模式匹配 |
| 与LLM关系 | 应用层与引擎层,整车与发动机 |
| 底层技术 | 微调、RLHF、智能体架构 |
| 局限性 | 上下文有限、幻觉、安全风险 |
重点强调
会用它不等于懂它:理解原理才能更好地使用和应对面试
AI编码助手是辅助工具,不是替代者:核心竞争力仍是你的架构能力和业务理解
面试时记住一条逻辑链:预训练→微调→上下文→生成→过滤→建议
系列预告
下一篇我们将深入讲解 AI编码助手中的代码智能体(Coding Agent)架构,拆解“收集上下文→采取行动→验证工作→循环”的完整链路,结合实际案例演示如何用Agent完成端到端开发任务。敬请关注。
本文内容基于2026年4月的最新行业信息与公开技术资料整理,力求客观准确。